
Before Reading:
- Although ProtoPNet can apply different backbones in their model, this is still an intrinsic approach for explainability, which means it require a very specific architecture to generate explanations.
ProtoPNet
The author gave the figure below in the paper to explain the over architecture of ProtoPNet, but I found it confusing until I read through the whole paper 😂. However, the ideas and formulas they proposed make this paper so pleasing to read.
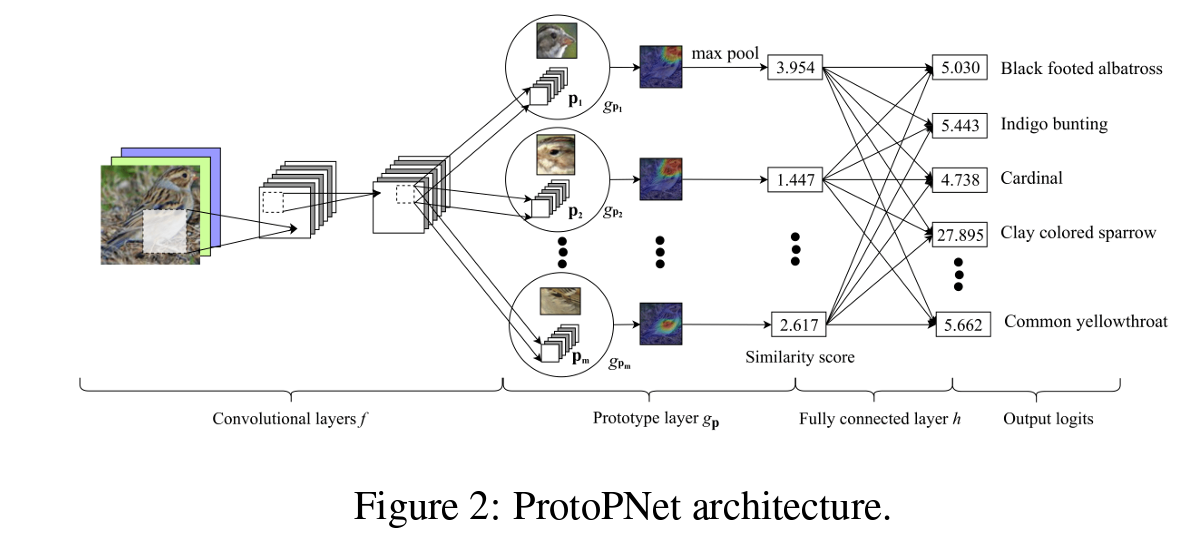
To express the architecture in the way I’m familiar with, this will be:
 ‘
‘
- The input image is passed into a CNN backbone to get the feature map.
- The feature map is seen as several patches with size as 1 x 1 x D.
- Each patch is then compared to prototypes to calculate the similarity between them to obtain the similarity map (activation map).
- By max-pooling the similarity map, it will give us the similarity score for each patch.
- The similarity scores are then passed into the fully connected layer to get the final prediction.
Mathematically


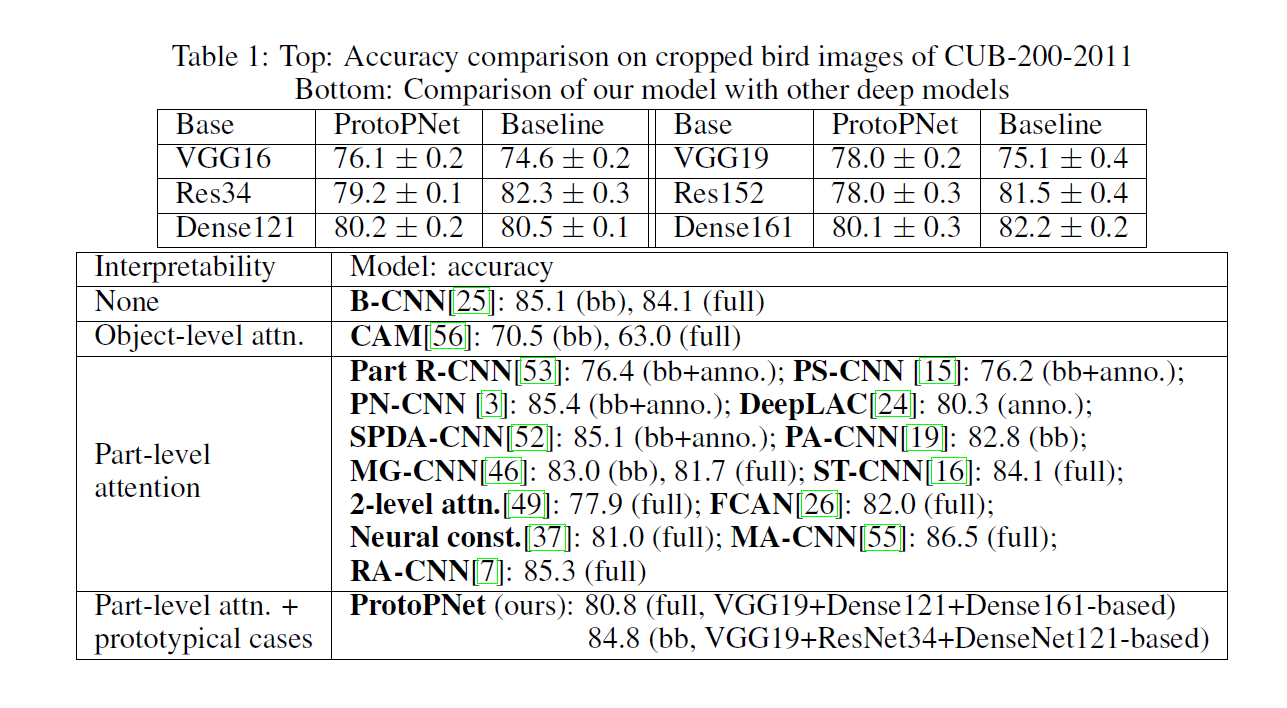
Result
References
[1] This Looks Like That: Deep Learning for Interpretable Image Recognition (https://arxiv.org/abs/1806.10574)