Before Reading
- This is not a typical XAI method for every case. It required a highly sepcific dataset to form the explanation.

- It is a work trying to find out how NN work internally but not to study why a model get a specific prediction. (I frogot the terms for these two types of XAI methods🥲)
Overview
- Dataset. Explaining what kind dataste is required for performing NetDissect. (It it super hard to get a dataset like this for your work, and this is why NetDissect is not the one to use for explaining other common tasks.)
- Model. Simply metion what type of model can be applied to NetDissect.
- NetDissect. Talk about what NetDissect is and how does is applied to the model.
- Results. Show the results of NetDissect.
Dataset
This work created a new dataset, Broadly and Densely Labeled Dataset (Broden), which is made by multiple scene, texture and color dataset to form the idea of visual “Concepts”.
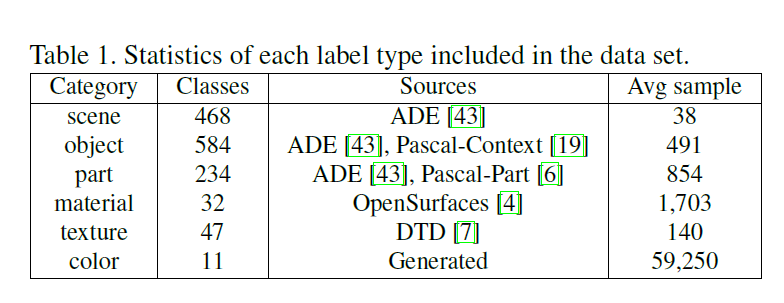

Dataset Requirement for NetDissect
To train the model and generate its neoron explaination using NetDissect, it required the dataset to have following contents.
- Images
- Segementations of concepts for calculating IoUs
- Labels of concepts
Model
This work is task- and model-agnostic. It requires only the dataset to be annotated with concepts, which is usually the hardest part of ML. Although it claim to be model-agnostic, your model still need 2 things:
- Have nuerons accessible for us to observe its behaviour.
- Can generate heatmaps of Class Activation Mapping (CAM), which means the model are differentiable for calculating gradients.
Which means, it will be a method used for Neural Network mostly.
NetDissect
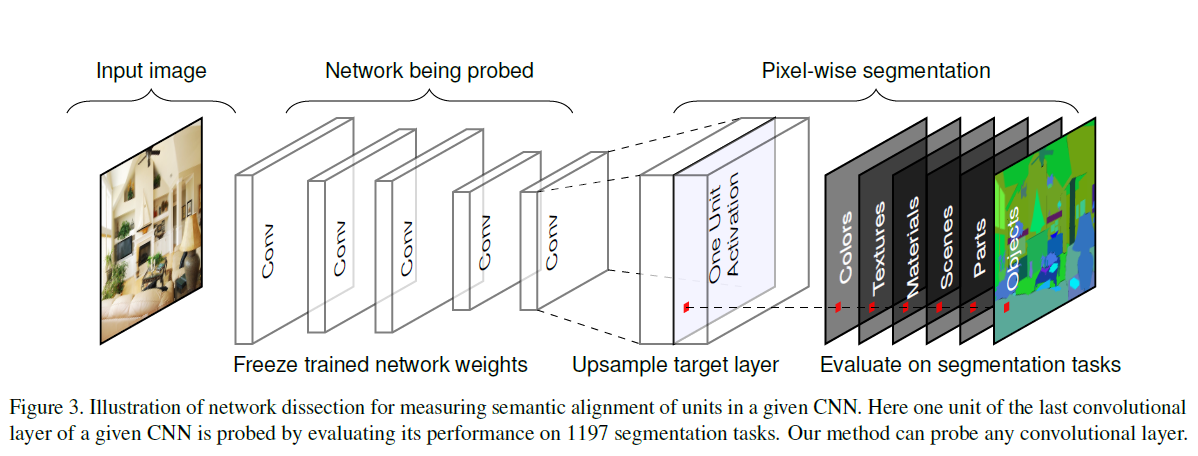
As we have mentioned the datasets in previous section, the NetDissect is pretty straightforward. Let’s go through the whole procedure pretty quick:
- Train. As usual, you will need train the model first. And, the requirements of model and dataset are stated in previous sections.
- Obtain activation maps. Once having trained model, we then generate the activation map for each input image.
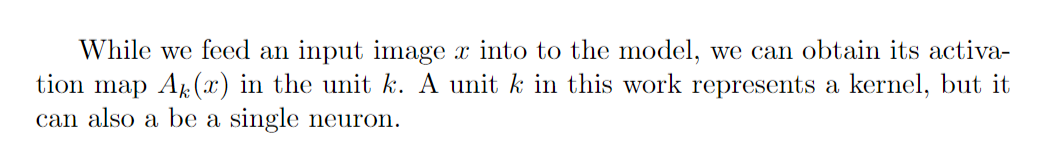
- Scaled it to the input image size. By aligning the activation map, we can know which part of image activate that specific neuron most.

- Tranform activation maps to masks. Activation maps are then transform into masks by upsampling to the image size and only selecting the parts of image that activate the unit (channel).

- Calculate IoUs. By using masks generated in previous step and segmentation labels from Broden dataset, we can calculate the IoUs between each unit and Concepts.
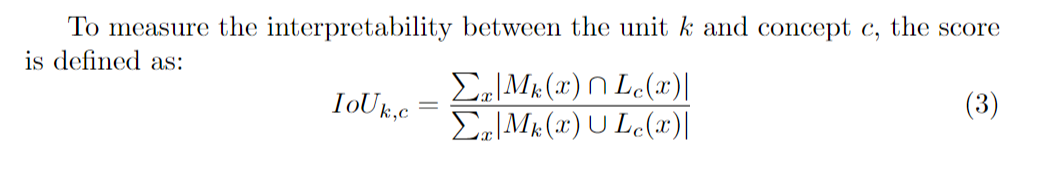
- Determine concepts for units. If the IoU value between the unit and the concept is above a threshold, we can say this unit is a detector for the concept.
Results

References
- Network Dissection: Quantifying Interpretability of Deep Visual Representations (https://arxiv.org/abs/1704.05796)